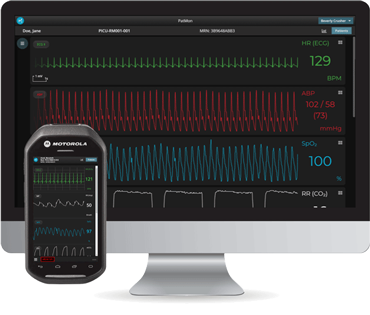
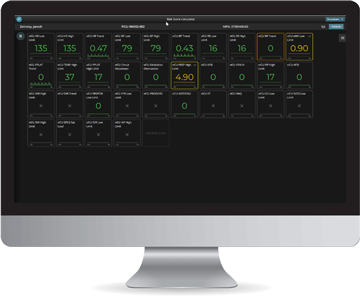
If you’re in the Department of Anesthesiology and Perioperative Medicine at UAB, you’ve probably heard about the high-resolution device integration, data-capture, and analysis platform called, “Sickbay.” Indeed, it is unique in its ability to chart and record, in a time synchronized fashion, any and all physiologic variables from our OR and critical care monitors and machines (ventilators etc.) at high frequency. But what can you do with it?
Currently, our usage is exclusive to the Cardiovascular Operating Room (CVOR) and Neuro ICU (NICU). In the CVOR Sickbay can be used for research purposes. In the NICU, it can be used for research and remote monitoring.
As one example of research — championed by Domagoj Mladinov and Dan Berkowitz — in the CVOR we’re currently using the platform to analyze high-resolution Near Infrared Spectroscopy (NIRS) and Arterial Blood Pressure (ABP) (at 120Hz) signals to estimate patients’ lower limits of cerebral autoregulation. That is, we want to identify the optimal blood pressure for each individual patient (precision medicine and goal-directed therapy) rather than targeting blood pressure based on commonly accepted population-based standards. Similarly, for NICU patients with Intracranial Pressure Monitoring (ICP), we can calculate optimal blood pressure from a combination of ABP and ICP signals. Both interventions would have a goal of improving brain perfusion by individualizing blood pressure (and other) therapies.

In the NICU, the platform is available for remote monitoring such as Gas Monitoring (e.g., respiratory rate), ECG Signals, Hemodynamics (e.g., arterial blood pressure), Temperature, CNS Monitoring (e.g., EEG). It can also provide continuous up-to-the-minute information trends from a patient’s entire (monitored) stay.
Sickbay also has the capability to use retrospective data to create risk-calculators that can be viewed from anywhere you can access the internet.
Finally, Sickbay has a built-in process for tracking and reporting all signals for patients enrolled in a study. All you need is a list of enrolled MRNs for your IRB-approved study that can be easily imported.
If you’re a faculty member in the department and are interested in applying this technology to your clinical practice or research project, feel free to reach out to Ryan Melvin (Principal Data Scientist), to learn more about Sickbay. Additionally, if you’re a faculty member from another UAB department and want to know more about potential collaborations involving Sickbay, reach out as well.