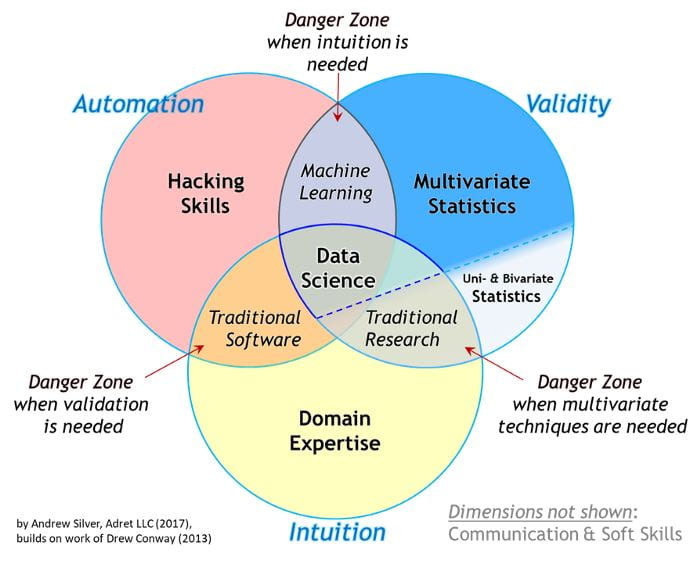
Machine learning and statistics both have procedures for making predictions and exploring relationships. Trying to explain the differences in the two often feels like debating semantics. However, there are some practical differences that can often prove frustrating to those encountering them for the first time. Here I try to concretely differentiate the types of questions that each field is better at answering.
Machine learning tends to do better at predicting future values (with some notable exceptions when it comes to medical data [1]). In a practical sense, machine learning models sacrifice interpretability for predictive accuracy. For example, a machine learning model could predict what a patient’s glucose level will be a few hours from now [2], monitor for cardiac arrhythmia’s in real time [3], use a patient’s own baseline data to determine abnormal vital signs [4], recommend insulin doses [5], and so on. However, if you ask for an explanation of how the model arrived at a prediction or recommendation, a cold black box will stare back unblinkingly with no answer. Machine learning is typically best for predictions, but it tends to be bad for explaining the relationships in data.

Statistics tends to do better at detecting relationships in data and quantifying the significance of those relationships. So, if you want to show an intervention caused a significant change in patient outcomes, that’s a statistics question. If you want to know if your new score card accurately predicts sepsis, that’s a statistics question. If you want to show that a policy change resulted in different outcomes over time, that’s a statistics question. Hypothesis testing is the realm of statistics. Often these hypotheses and detected relationships imply predictions of future values (e.g., logistic regression), but statistical models prioritize interpretable relationships over predictive accuracy.
Next, let’s consider a few examples where the distinction is subtle. Suppose you’ve come up with a new index for predicting hyperglycemia. Testing whether the index performs well is a job for statistics. However, if you want to develop a new index from scratch, machine learning can help out.
Maybe you have five factors that you know lead to respiratory distress after surgery. If you want to know how much each of those factors influences the outcome, your project is best served by statistics. However, if you want the most accurate prediction of the outcome possible without needing to know the influence of each factor, that goal is in the realm of machine learning.
If you find yourself asking how multiple pieces of data relate to one another, statistics is the tool for you. However, if you are looking for predictions of an outcome and don’t need to know detailed reasons for the predictions, that’s a job for machine learning.
References
[1] Christodoulou, E., Ma, J., Collins, G. S., Steyerberg, E. W., Verbakel, J. Y., & Van Calster, B. (2019). A systematic review shows no performance benefit of machine learning over logistic regression for clinical prediction models. Journal of Clinical Epidemiology, 110, 12–22. https://doi.org/10.1016/j.jclinepi.2019.02.004
[2] Abraham, S. B., Arunachalam, S., Zhong, A., Agrawal, P., Cohen, O., & McMahon, C. M. (2019). Improved Real-World Glycemic Control With Continuous Glucose Monitoring System Predictive Alerts. Journal of Diabetes Science and Technology. https://doi.org/10.1177/1932296819859334
[3] Rajput, K. S., Wibowo, S., Hao, C., & Majmudar, M. (2019). On Arrhythmia Detection by Deep Learning and Multidimensional Representation. 2. http://arxiv.org/abs/1904.00138
[4] Stehlik, J., Schmalfuss, C., Bozkurt, B., Nativi-Nicolau, J., Wohlfahrt, P., Wegerich, S., Rose, K., Ray, R., Schofield, R., Deswal, A., Sekaric, J., Anand, S., Richards, D., Hanson, H., Pipke, M., & Pham, M. (2020). Continuous wearable monitoring analytics predict heart failure hospitalization: The link-hf multicenter study. Circulation: Heart Failure, March, 1–10. https://doi.org/10.1161/CIRCHEARTFAILURE.119.006513
[5] Nimri, R., Oron, T., Muller, I., Kraljevic, I., Alonso, M. M., Keskinen, P., Milicic, T., Oren, A., Christoforidis, A., den Brinker, M., Bozzetto, L., Bolla, A. M., Krcma, M., Rabini, R. A., Tabba, S., Smith, L., Vazeou, A., Maltoni, G., Giani, E., … Phillip, M. (2020). Adjustment of Insulin Pump Settings in Type 1 Diabetes Management: Advisor Pro Device Compared to Physicians’ Recommendations. Journal of Diabetes Science and Technology. https://doi.org/10.1177/1932296820965561
