The NIH’s massive data collection initiative All of Us allows researchers access to data from multiple institutions.
If you’ve ever envisioned a project only to find out that UAB doesn’t have sufficient numbers for the statistical power you’re after, it may be worth checking out the researcher workbench in All of Us.
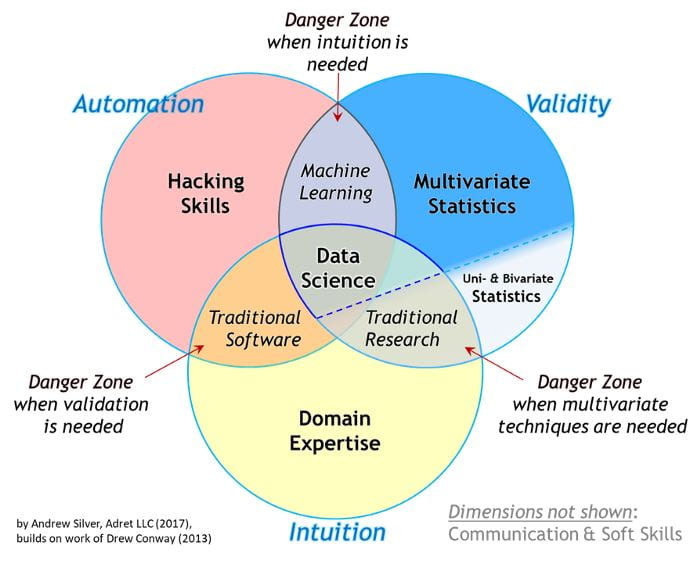
While large parts of the workbench are designed with Data Scientists and Statisticians in mind, there are some key parts that don’t require knowledge of a coding language or the construction of database queries. Here I outline two of them.
The Data Browser
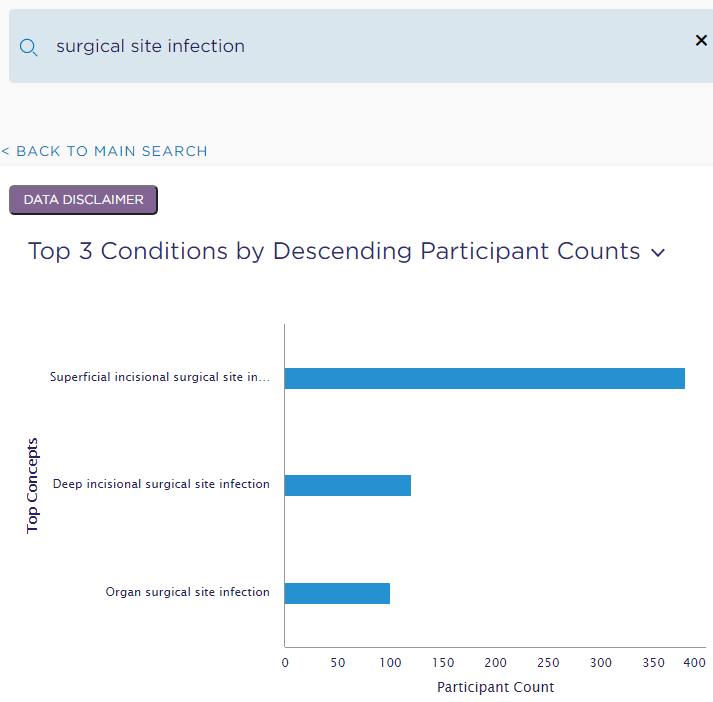
Even without an Alll of Us researcher account, you can search for a condition (e.g., Surgical Site Infection) or measurement (e.g., metabolic panel) and immediately be presented with the number of All of Us patient participants matching your search. For example, search for “surgical site infection” found 600 participants with a condition matching my search (see breakdown below).
Similarly, a search for “metabolic panel” found 7 matching lab measurements across about 45,000 participants.

These high level counts are available on the public portion of the website. So, you can find out if there’s a sufficient sample size to warrant applying for access to the researcher workbench and applying for IRB approvals and waivers as necessary.
One other handy tool in the Data Browser are the “matching concepts.” Here are the top 3 matching concepts that were returned in my search for “metabolic panel.”
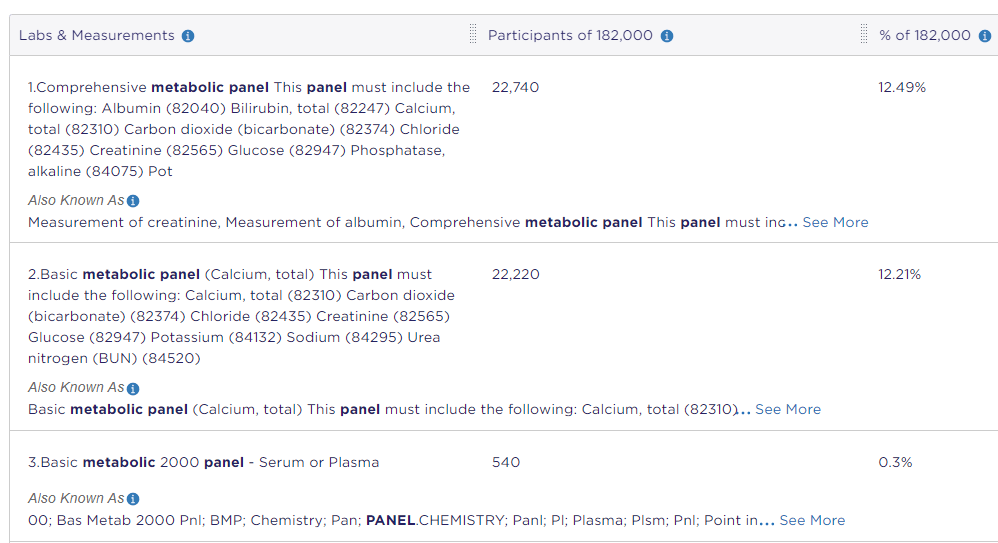
These can be helpful when requesting data either from our internal Anesthesiology and Perioperative Medicine IT team or HSIS. You can potentially skip the part where the data person is confused about what you mean by first searching in the All of Us data browser and including the matching concepts that fit what you’re looking for. I myself have done some of this with our internal IT team, so I know it can be a time saver.
For more information on the All of Us researcher workbench, check out their publicly available description and videos: Researcher Workbench – All of Us Research Hub (researchallofus.org).
The Cohort and Dataset Builders
Sadly, I don’t feel comfortable giving screenshots here because of some of the researcher agreements that apply to All of Us. However, once you have an All of Us researcher account (and the appropriate IRB and regulatory approvals, if applicable), you can assemble a Cohort of All of US participants through the Cohort Builder and access their collected EHR data through the Data Set Builder. If you do those steps, you’ll probably be at a place where you want the help of a Data Scientist or Statistician. But, you can arrive at your first meeting with them with data in hand. Talk about speeding up a project!
i2b2
Internally, UAB has a similar initiative called “i2b2.” It can provide information about potential sample size (and statistical power) for projects you may envision. I’ll cover some of the useful bits of i2b2 in a future post. Stay tuned!