AI in the Era of Distributed Learning
In the advancing frontier of Artificial Intelligence (AI) and distributed learning, a pivotal challenge emerges from stringent data security and localization laws. These regulations, increasingly adopted worldwide, limit the cross-border transfer of sensitive information. While definitions of sensitive data vary from one nation to another, a common thread is their expanding scope. Such restrictions pose notable barriers to the seamless exchange of data, crucial for global collaboration in AI research and application. Our pioneering representative approaches are ingeniously designed to navigate these hurdles, enabling robust AI and distributed learning analysis within the framework of current data localization mandates. By leveraging compact, representative data points that encapsulate essential data characteristics, we offer a pathway to continue cross-border collaborations effectively, ensuring that the evolution of AI and distributed learning is not impeded by legislative barriers.
Representative Learning
In tackling the inherent challenges of traditional Federated Learning (FL), such as communication inefficiency, data heterogeneity, and security vulnerabilities, we introduce a groundbreaking framework: Representative Learning (RL). Conceptualized to transcend FL’s limitations, RL employs data abstractions called representatives—pseudo data points meticulously designed to preserve the critical features of each local node’s dataset. This innovative approach enables efficient central analysis, drastically reduces data movement, and significantly enhances privacy and security measures.
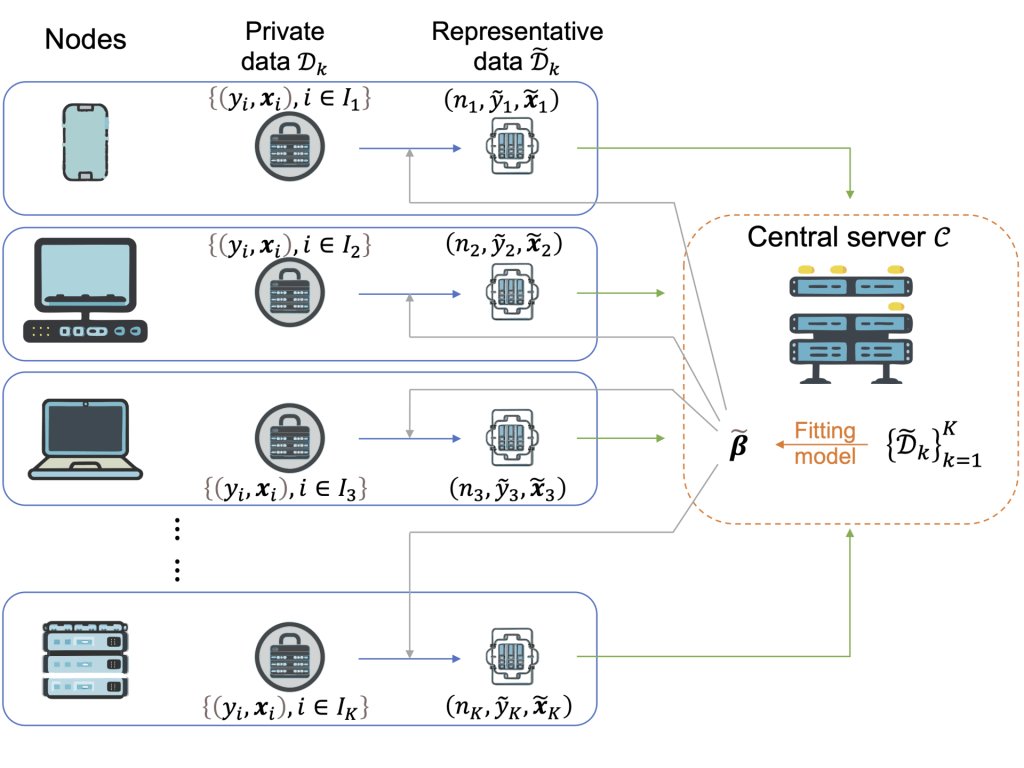
RL stands out by substantially lowering communication demands through these compact representatives, thereby boosting the scalability and adaptability of AI systems in distributed settings. It expertly accommodates data diversity, facilitating the application of varied models or methodologies across nodes for targeted, synergistic problem-solving. Such flexibility is indispensable in distributed environments, where the demands for privacy, efficiency, and versatility are paramount.
Our exploration into RL has yielded two pioneering methods: the Mean Representative (MR), which leverages local means for representation in a model-free manner, and the Score-Matching Representative (SMR), outlined in Li and Yang (2022), adopting a model-based strategy to ensure score function values align across nodes. The SMR’s efficacy is further enhanced by the Response-Aided Score-Matching Representative (RASMR), which improves data partitioning through response integration, facilitating unique representatives and enabling sophisticated analytical techniques.
Building on these foundations, the Anchored Score-Matching Representative (ASMR) represents our latest advancement, targeting previously identified constraints within SMR to foster more stable and efficient representative generation. This evolution underscores RL’s potential to revolutionize distributed learning, as demonstrated through pilot studies, offering a robust solution for AI applications in fields ranging from smart manufacturing to healthcare, and beyond.
